Introduction
Sqoop is a component of the Hadoop ecosystem that facilitates the transfer of data between Hadoop and structured data stores such as relational databases. It stands for "SQL-to-Hadoop" and is designed to efficiently import data from databases into Hadoop Distributed File System (HDFS) and export data from HDFS back to databases.
Sqoop provides a command-line interface and supports connectivity with various relational databases, including MySQL, Oracle, PostgreSQL, SQL Server, and many others. It allows users to import data from database tables or entire database schemas into Hadoop, where the data can be processed by other Hadoop components like MapReduce, Spark, or Hive. Similarly, Sqoop enables exporting data from HDFS to a database, which can be useful for integrating Hadoop with traditional data processing systems.
Some key features of Sqoop include:
Efficient data transfer: Sqoop uses parallel data transfer mechanisms to import and export data, which helps achieve high performance and scalability. It can split data into multiple chunks and transfer them in parallel, utilizing the available network bandwidth effectively.
Automatic schema inference: Sqoop can automatically infer the schema of the imported data based on the source database's metadata. It can also apply transformations to convert database-specific data types to appropriate Hadoop data types.
Incremental imports: Sqoop supports incremental imports, allowing users to import only the data that has been added or modified since the last import. This feature is particularly useful when dealing with large datasets that are regularly updated.
Integration with security mechanisms: Sqoop integrates with Hadoop's security framework, enabling authentication and authorization mechanisms like Kerberos and Hadoop Access Control Lists (ACLs). It ensures secure data transfer and access control between Hadoop and databases.
Extensibility: Sqoop provides extensibility through connectors. Additional connectors can be developed to support different database systems or enhance the functionality of Sqoop.
Overall, Sqoop simplifies the process of transferring data between Hadoop and relational databases, making it easier to leverage the power of Hadoop's distributed processing capabilities on structured data.
Let's deep dive into Sqoop further.
Sqoop Import
Sqoop import imports individual tables from RDBMS.
Each row in a table is treated as a record in HDFS.
Records can be stored in text file format, sequence file format, Avro and parquet file format.
Sqoop Export
Sqoop export exports a set of files from HDFS back to RDS.
The target table must already exist in the database.
Files are read and passed into a set of records according to the user-specified delimiters.
sqoop eval - To run queries on the database.
Basics
As we deal with RDBMS here in sqoop.
To enters into RDBMS
MySQL -u root -p
(we are trying to login in as root user)
Root user:- Have access to all the database
My -u retail_dba -p
retail_user has access to the limited database.
(A) to exit from MySQL use the command: exit
(B) to clear:- ctrl+l
(C) to list the DB:- show the database
(D) to use a particular db:- use retail_db (DB name)
(E) to show/view the table:- show tables
What if we don't have connectivity/interface to DB in our Hadoop terminal?
\ - indicates that the next line is in continuation
(there shouldn't be any space after the backslash)
To list the database

Where ''quickstart.cloudera'' is HOST NAME, in actual production this will be replaced by the IP Address where SQL Server is running.
:3306 is the default port number for MySql.
When we don't want to show a password (hardcoded) then we will use --p instead of --password.
To list down the tables

Display table data using sqoop-eval
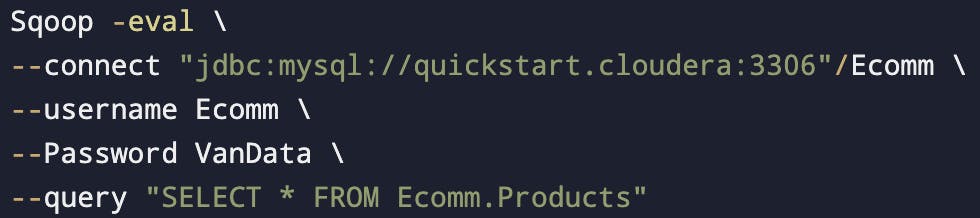
- We can use --e instead of --query, both functions are the same.
Sqoop import
Create a database
Create table
Insert values into the table, after inserting the query we need to use 'commit'.
MySQL is a traditional DB inside it we need to use commit to store the data in the table.
In sqoop MapReduce will work. In the MapReduce job, only mappers will work and no reducers (as there is no aggregation happening here)
By default, there are 4 mappers and we can change the no. of mappers.
Work will be divided based on the primary key.
If there is no primary key, then:-
(A) Change the no. of mappers to 1 (won't divide the work we are restricting the parallelism.
(B) Split by column: We will indicate a column to split the work among the mappers. We also use split-by when the PK is not evenly distributed.
How does it work?
Two things to keep in mind when using split by:
(I) It shouldn't have outliers.
(II) It should be indexed, if it isn't indexed then it will go for full table scan unnecessarily.
Split by column should have 'Numeric Values'. It is not recommended to use split by on a text column.
Dealing with SPLIT BY or PK on Non-Numeric fields
(I) By default sqoop import will fail. To avoid that we should use
org.apache.sqoop.splitter.allow_text_splitter = true(II) It is also applicable when we use non numeric field as a part of split by clause.
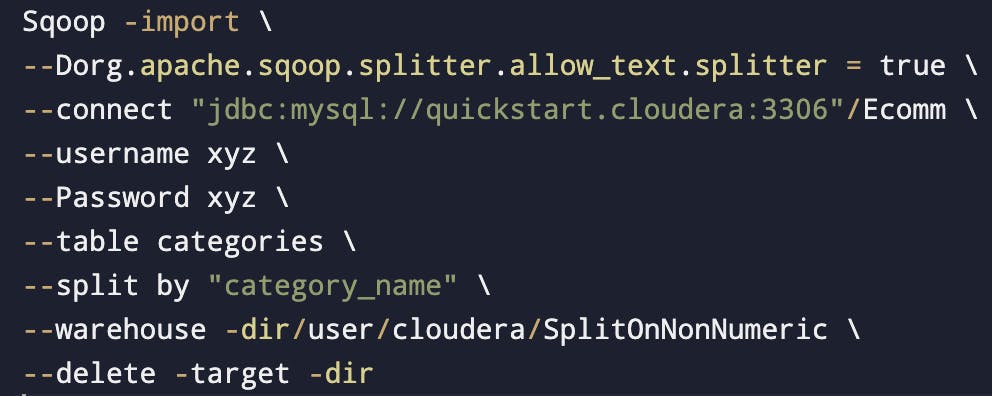
In line 2, -D indicates the start of the property & property starts from org.
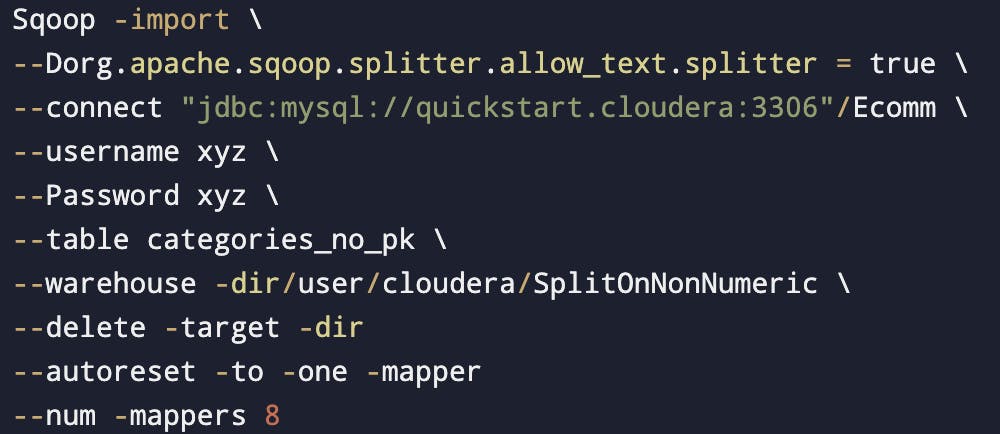
Auto reset to one mapper
--autoreset - to -one-mapper
--num-mappers 8
(If there will be no PK it will use one mapper & if there will be a PK then it will use 8 mappers)
(Both these properties will be used at the end).
When the primary key is available
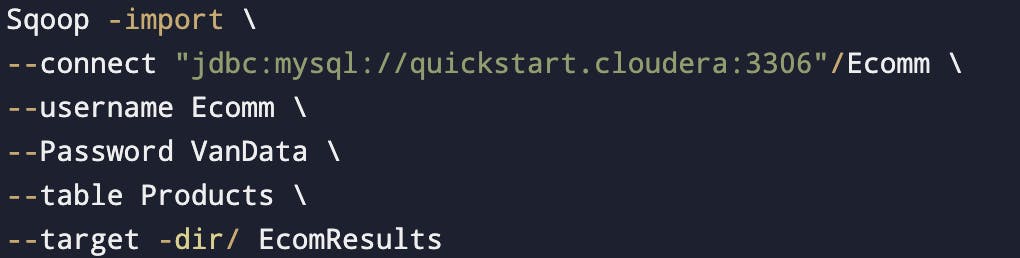
This Product table is under Ecomm Database.
EcomResults: HDFS path where the data will come and this shouldn't be an existing path/directory.
Hadoop fs-ls / EcomResults (This is where we can find the import table/file)
Hadoop fs-cat / EcomResults / * (To see the content inside the files)
(* means all the files/record)
When no primary key is given
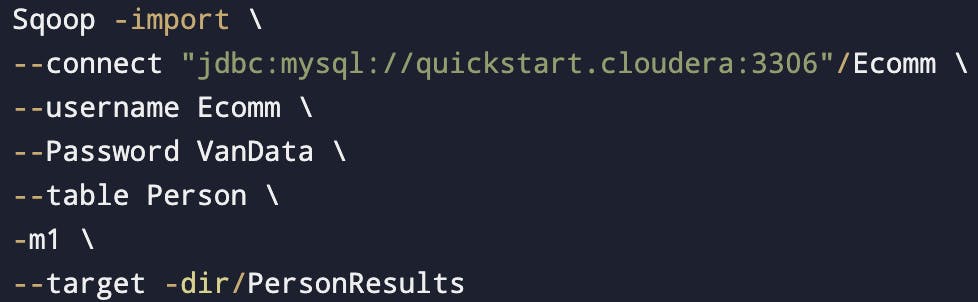
-m1 indicates only one mapper is being used.
we can use -m1 or --num -mapper 1, both are same.
To import all the tables
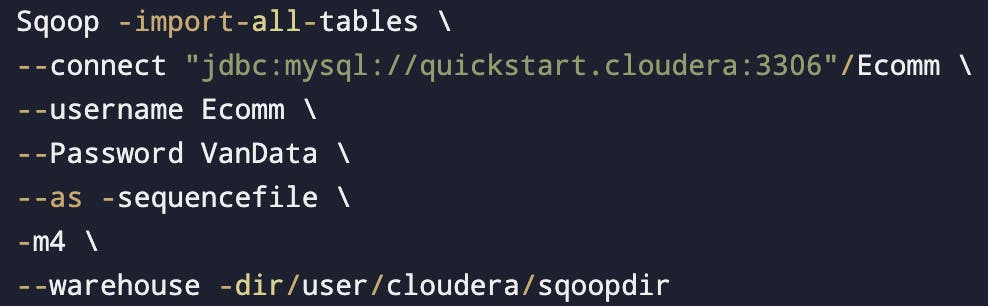
What's the difference between the Target directory and the Warehouse directory?
Target directory: In the case of target directory the directory path mentioned is the final path where data is copied.
Target directory won't work when we will import all the tables. (import-all-tables)
- Eg. Class/data
Warehouse directory: In the case of warehouse directory, the system will create a subdirectory with the table name.
- Eg. Class/data/Students
Sqoop supports 4 types of file format
Text
Sequence
Avro
Parquet
(If we don't mention, by default it will take text file format)
To check the file structure in HDFS
hadoop fs -ls / PersonResults /
Redirecting logs
Logs that are redirected on the screen will be put into some files.
As we won't be there when these will be production-ready, thus logs will be in a file and can be seen anytime.
The file will be available in the current working directory.
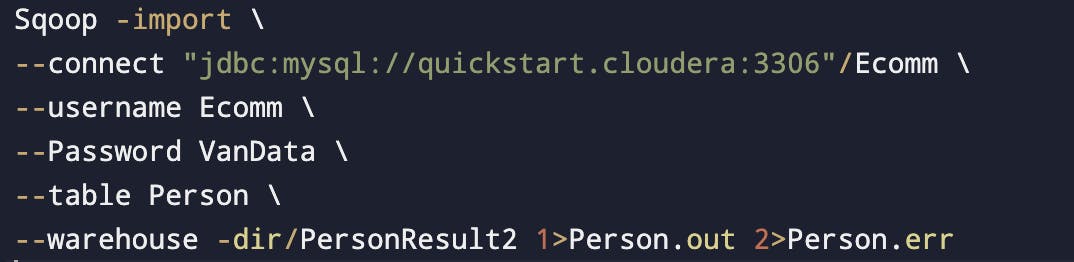
Person.out - Will have output message.
Person.err - All other messages.
To check the contents of log files: Cat query.out & Cat query.err
These names can be anything, whatever the developer wants (Person.out, Person.err)
Boundary Query/ Bound well query
So, in sqoop import the work is divided among mappers based on the primary key.
By default we have 4 mappers, How do they divide their work?
Internally it will work to run the query to find
{a} Max of the primary key (PK)
{b} Min of the primary key (PK)
Split size = (Max of PK - Min of PK) / No.of mappers
For eg. Split size = (1000-0)/4 = 250
Each mapper will work on 250 rows
This is known as the "Boundary key".
How do mappers divide their work when a query is fired?
Selects one record and by using that it gets the metadata and builds the java file. (Basically, it gets the DataType)
Using the above java file it builds the jar file.
Bounding Vals query
Based on Max & Min on PK.
Calculates (Max-Min)/4 & it gets the split size.
Once all this is done it will submit the job to MapReduce.
Boundary query for "NON-PK"
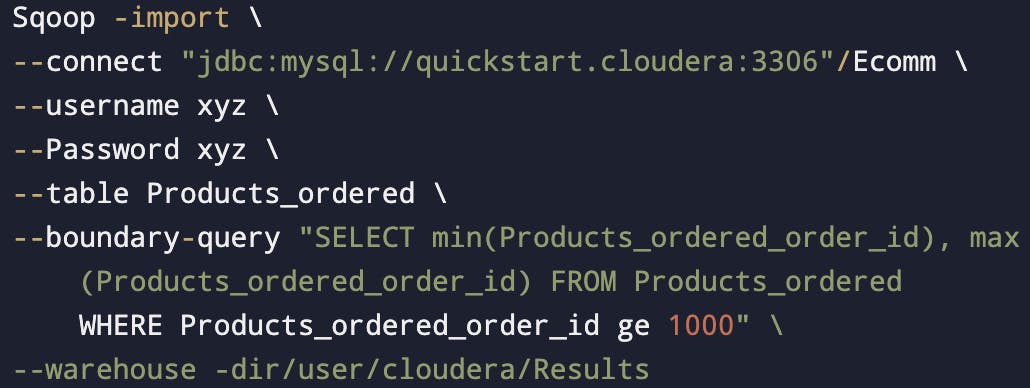
WHERE Clause also internally treated as BoundaryVals query
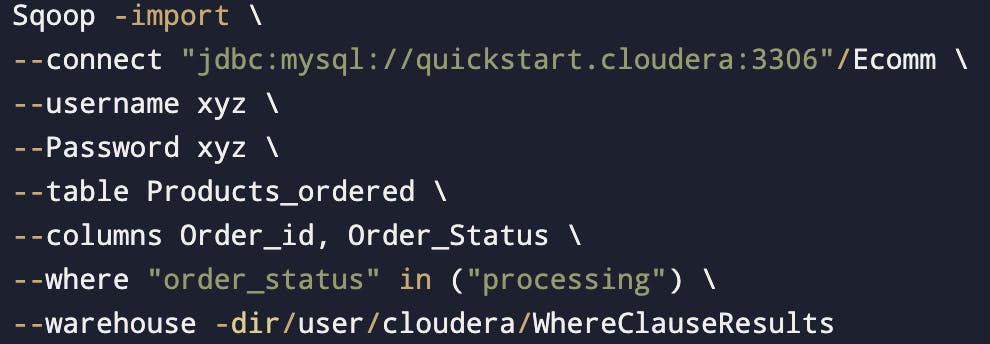
--columns: The columns which we want to import.
WHERE clause query will become part of boundary query(This can be seen in the logs)
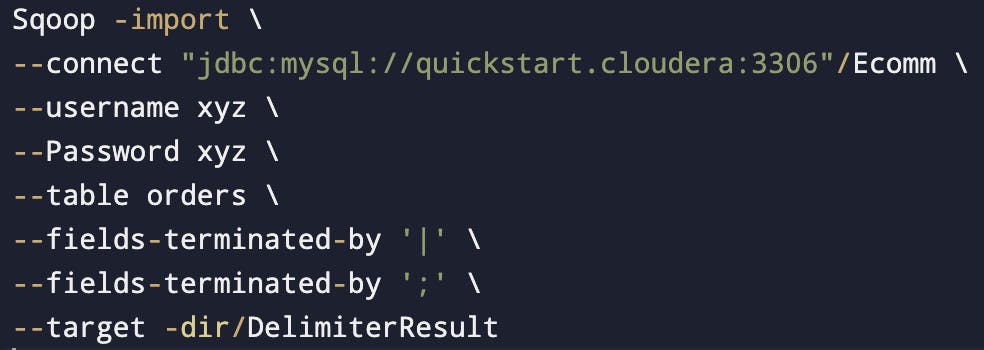
Delimiters
Delimiters are specified by the following arguments:
--fields-terminated-by <char>
--lines-terminated-by <char>
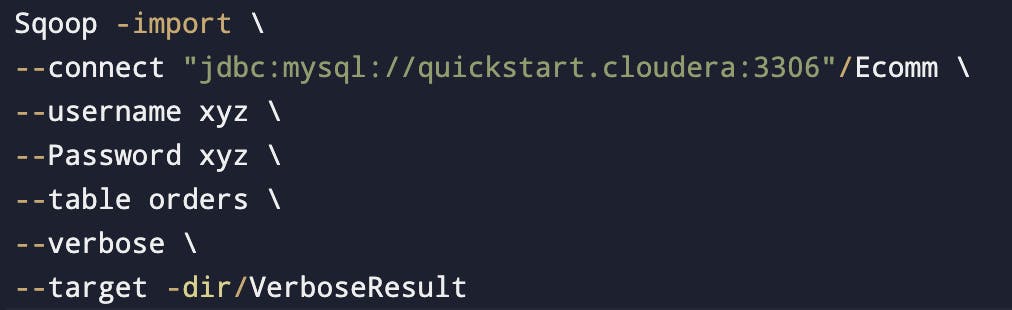
Sqoop Verbose
Run sqoop verbose job with the --verbose flag to generate more logs and debugging information.
Gives extra information, what all are the queries mappers are using.
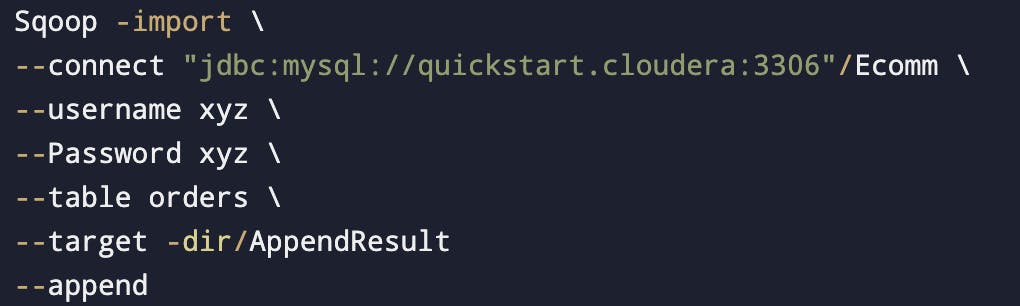
Sqoop Append
By default, imports go to a new target location. If the destination directory already exists in HDFS, sqoop will refuse to import.
The --append argument will append data to an existing dataset in HDFS.
Suppose we already had 6 files then it will also load the new files at the same directory.
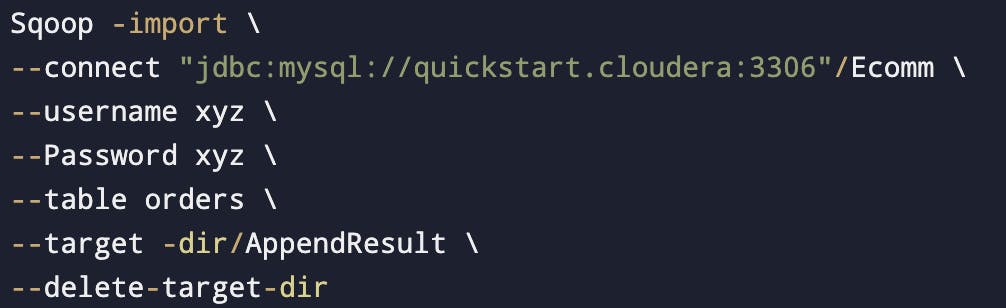
Delete target directory
It will delete the old data and import the data for which the argument ran.
It's like overriding the data.
Whenever we will run this we will see new data, not the previous ones.
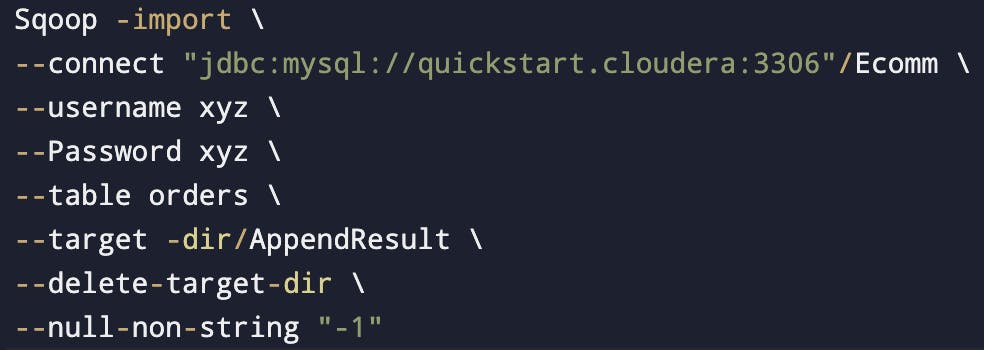
Dealing with nulls while importing
When we import data into text files, we might have to explicitly deal with the null values.
we can specify non string nulls using --null-non-string and string nulls using --null-string.
Below code will replace any null value then replace that with 1.
Incremental Import
(This works for the delta load)
Delta load: We are loading any data for the 2nd time or onwards.
We have two options
(I) Append mode: Append mode is used when there are no updates in data and there are just new entries/inserts.
(II) Last modified mode: When we need to capture the updates also. So, in this case we will be using a date on a basis of which we will try to fetch the day when those updates are available.
Three important parameters
(I) --check-column(col)
(II) incremental(mode)
(III) --last-value(value)
Append
Specify the column containing the row id's with --check-column.
Sqoop imports rows where the check column has a value greater than one specified with --last-value.
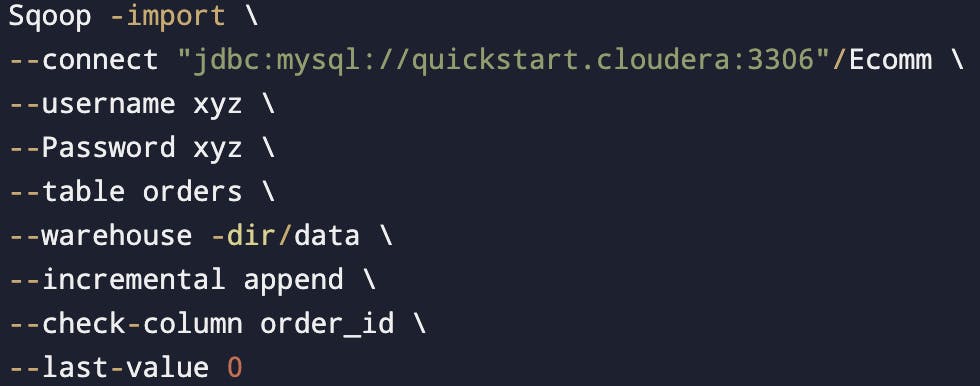
It will check order_id and pull all the records which have order_id > 0.
Manual involvement will be there to keep the track of last value inserted. (We can check it from the log)
Date can also be put in the last value
It will use a boundary query.
For eg :
SELECT MIN(order_id), MAX(order_id) FROM orders
WHERE ('order_date' = 'xyz' AND 'oder_date' < abc){xyz will be last updated time & abc will be current time}
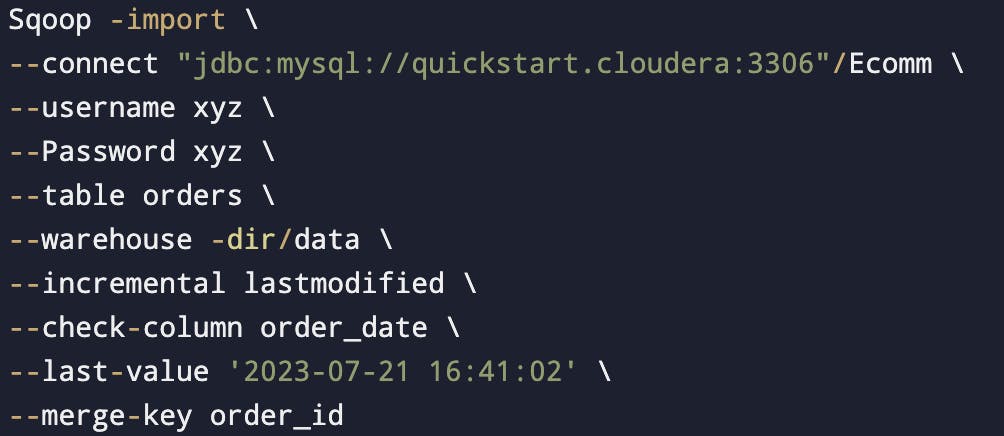
Last modified mode
To use when rows of the source table may be updated and each such update will set the value of a last modified column to the current timestamp.
Rows where the check column holds a timestamp more recent than the timestamp specified with --last-value are imported.
(In this parameter we will specify/mention the last timestamp)
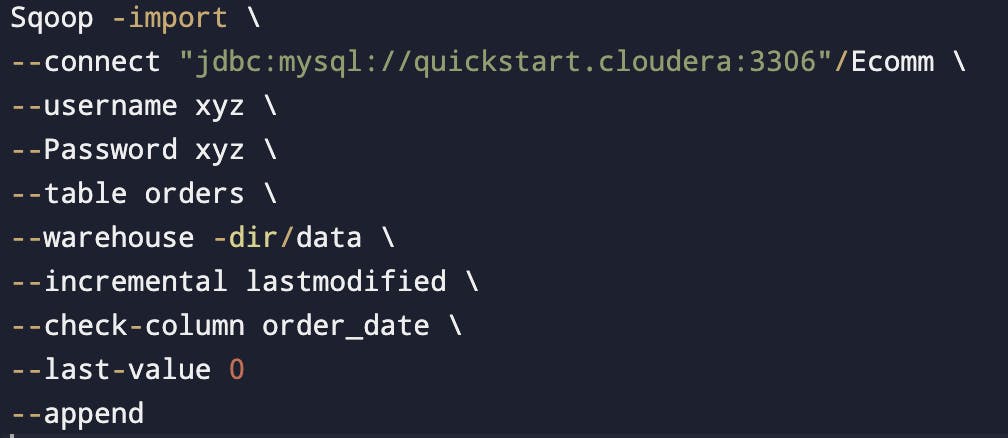
If a record is updated in your table and then we use incremental import with the last modified, then we will get the updated record also.
Eg. 500 old timestamp records in HDFS, now after this we have 200 new timestamp records in HDFS
We want our HDFS file should always be in sync with the table
Append will result in a duplicate record in the HDFS directory
What if we just want to get the latest records in HDFS?
In this case, we need to use a merge
Merge: To get the latest version of that record
--merge-key (merge column)The merge tool will "flatten" two datasets into one, taking the newest available records for each primary key.
The merge tool is typically run after an incremental import with the date-last-modified mode.