



Introduction
Hadoop, an open-source distributed computing framework, has revolutionized the way we handle big data in the digital age. Developed by the Apache Software Foundation, Hadoop provides an efficient and scalable solution for processing and analyzing vast amounts of data across clusters of commodity hardware. Its architecture is designed to address the challenges posed by the explosion of data in various industries, offering an innovative approach to storage and processing that can be applied to diverse data types.
At its core, Hadoop architecture is based on two key components: the Hadoop Distributed File System (HDFS) and the MapReduce programming model. These fundamental elements work in tandem to enable distributed storage and parallel processing of data, making Hadoop a versatile and reliable framework for handling massive datasets.
In this introduction to Hadoop architecture, we will delve into the key components, their roles, and how they collectively create a robust foundation for scalable data processing. Additionally, we'll explore how Hadoop's fault-tolerant design and flexible ecosystem of tools and technologies have made it a go-to solution for organizations seeking to extract valuable insights from their data while maintaining high availability and resilience. By the end of this overview, you will have a solid understanding of the Hadoop architecture's core principles and be better equipped to harness its power for handling modern data challenges.
MapReduce
A computing paradigm for processing data that resides on many computers is MapReduce, it is a particular way to solve the problem. Traditional programming model work when data is kept on a single machine but here that isn't the case thus we are using MapReduce.
It has 2 phases/stage
(I) Map phase - Gives us parallelism
(II) Reduce phase - Gives us aggregation
Both this map and reduce work only on the 'KEY' and 'VALUE' pairs.
Eg. (Employee name, Employee I'd)
(Anuj, 703289546)
(Ajay, 703286734)
Input (K, V) --> MAP --> Output (K, V)
Input (K, V) --> REDUCE --> Output (K, V)
What is the process of MapReduce?
The file is split into blocks and stored on a Name node
A mapping program (Map program-Java based) will be sent to all the name nodes as it is easy to move the program than blocks.
(Size of the blocks will be higher than the program)
Eg. We have a file of 1000MB, then we will have 8 blocks each having 128MB and the program is 40MB.
The above process is known as the map process and the running of a program is known as the mapper.
Hadoop works on data locality, which means that the data is processed where it is kept code will go to the data.
Mapper gives us parallelism, all the same program runs parallelly.
It doesn't need to always give us parallelism, it does depend on a number of name nodes or machines.
Record reader
(I) It will take each line as input and converts each line into a 'Key Value' pair
Eg. Bid data is future
How was your weekend
Watching the sunrise is a therapy
(II) Record reader takes the above lines as input and gives any (Key, Value) pairs as output.
(1, Bid data is future)
(2, How was your weekend)
(3, Watching the sunrise is a therapy)
This process is commonly known as Splitting.
Mapper
(I) Mapper ignores the keys, it only considers the values split based on space.
We as a developer have to write the logic for the map phase(Only focusing on value).
Eg. (How was your weekend, 2)
(How, 1)
(was, 2)
(your, 3)
(weekend, 4)
These are also in key-value pair as the map will give output in the form of key-value.
(II) Output from the name node is known as intermediate output.
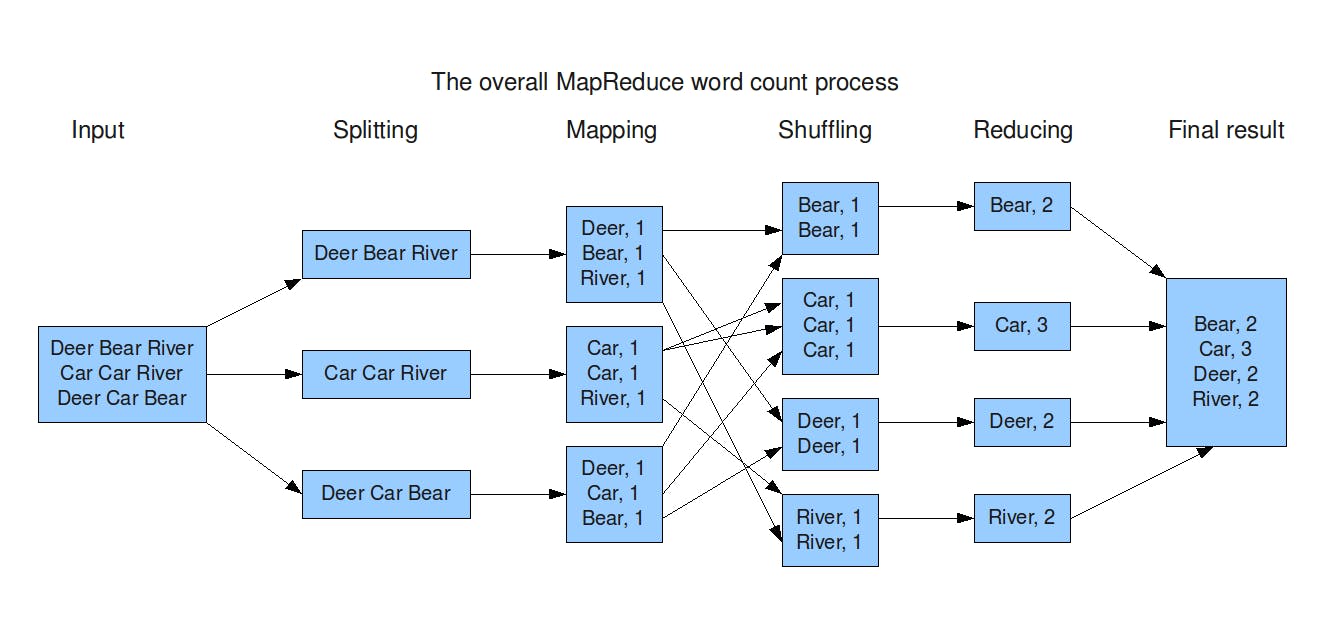
(III) Shuffle: All the key-value pairs will be in one machine
(IV) Sorting: It will sort the keys in ascending order.
Shuffling and sorting will be taken care of by the MapReduce framework.
(V) How many mappers should be launched?
Suppose we have a 1GB file then we will have 8 blocks/Name node.
No.of blocks = No.of mappers
Thus, we will require 8 mappers.
- Suppose we have just 5 nodes then not all the mappers are running parallel or not depending on hardware. It might not run but all the mappers will run.
Reduce
(I) Reduce will give the final aggregated value.
(II) How many reducers should be launched?
No.of reducer = Controlled by developer
By default, we have only 1 reducer but as a developer, we can change the no.of working reducer.
Changing the number of reducers
(a) When to increase
- All the mappers(let the mappers be five in number) are taking 5min to complete and the reducer is taking 15mins, then the total time = 20mins.
- We tried our best to move some computations from reducer to mapper
Now, 5 mappers are completed in 7mins and 1 reducer in 10mins, then the total time taken is 17mins
- Now we will increase the no.of reducer. We will make it to 2 reducers.
5 mappers will take 7mins and 2 reducers will take 5mins each parallely, now the total time is 12mins.
- So, whenever we feel our reducer is bottlenecked then we should go for increasing the number.
(b) When reducer is not required?
- Some jobs don't require aggregation. For eg. we need to filter, then only the mapper will filter, we don't need any shuffle/sort.
- Shuffle/Sort only happens when we have 1 or more reducers. So, when the no.of the reducer is zero then our output will be the final output.
Concept of Partition
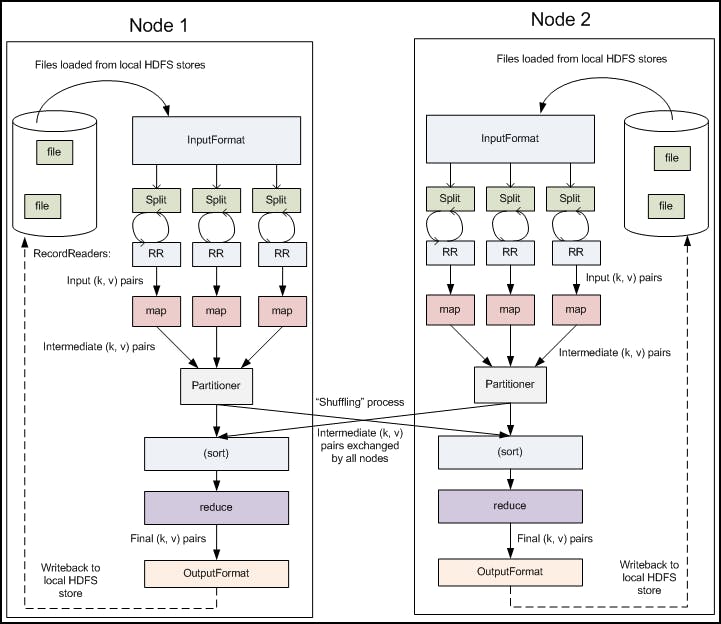
The partition will divide the no.of key-value pair and send it to the no.of reducers.
No.of partition = No.of reducers
We have a 'hash function' that tells us which key-value pair will go to which reducer. Let MOD as a hash function
Three Reducer - 0,1,2
1 % 3 = 1
2 % 3 = 2
3 % 3 = 0
So, Reducer 0 will have a value = 1
Reducer 1 will have a value = 2
Reducer 2 will have a value = 0
A hash function is consistent
- When a MapReduce job is executed, the consistent hash function determines which node in the cluster should be responsible for processing each data item. This assignment is based on the hash value of the data item and the positions of the nodes on the hash ring. By using consistent hashing, the distribution of data is not affected by the addition or removal of nodes in the cluster. Only a portion of the data needs to be remapped to different nodes when the cluster's size changes, minimizing the impact on the overall system.
- The consistent hash function also provides fault tolerance in MapReduce. If a node fails or is taken offline, the consistent hash function ensures that the data previously assigned to that node is redistributed to other available nodes. This redistribution is performed by identifying the next closest node in the clockwise direction on the hash ring.
What if the hash function is inconsistent?
When processing data in a distributed fashion, significant difficulties and problems can arise if the hash functions used by MapReduce are inconsistent. Inconsistent hash functions have the following effects:
- Uneven data distribution: Inconsistent hash functions can result in uneven distribution of data across cluster nodes. Excessive amounts of data can accumulate on a particular node, resulting in uneven workloads and poor processing efficiency. This can reduce the overall performance of MapReduce tasks.
- Load imbalance: Inconsistent hashes can lead to node load imbalance. Some nodes may be underutilized, while others may be overloaded with data and processing tasks. This can result in longer processing times, increased resource consumption, and reduced overall system efficiency.
- Inefficient resource utilization: Inconsistent hash functions can lead to underutilization of available computational resources in the cluster. Nodes with higher processing power may not distribute the workload fairly, resulting in underutilized resources and lower overall throughput.
- Fault tolerance challenges: Inconsistent hashing complicates MapReduce's fault tolerance mechanism. Redistribution of data becomes more complicated when nodes fail or are added/removed. Lack of consistency in hash functions can require extensive remapping of data, adding overhead and potentially impacting system availability.- Scaling difficulty: Inconsistent hashes can affect the scalability of the MapReduce framework. Adding or removing nodes from a cluster becomes difficult as it may require a complete rehashed of data distribution across nodes, which can cause disruption and potential performance degradation during the scaling process.
Combiner
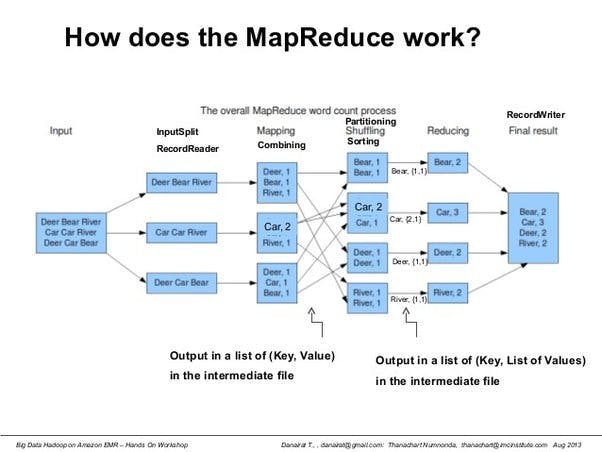
The combiner is an optional component in the MapReduce framework that performs a local reduction of intermediate key-value pairs before they are sent to the reduce phase. During the map phase, the mapper processes input data and generates intermediate key-value pairs. These pairs are then grouped by their keys and transferred to the reducers for further processing. The combiner comes into play after the mapping phase, just before the shuffle and sort phase.
The combiner function, which is essentially a mini-reducer, operates on the intermediate key-value pairs locally within each mapper's output. It combines or aggregates values with the same key to produce a reduced set of intermediate key-value pairs. By doing so, it reduces the volume of data that needs to be transmitted over the network to the reducers.
Advantages
Improves the parallelism
Reduce the data transfer time
Combiner: Works on data from mapper
Reducer: Works on entire data
Summary
The internal logic between the Map and Reduce functions is very complicated. I will use the terminology used in the book "Hadoop Definitive Guide". All the logic between the user's map function and the user's reduce function is called the shuffle. Then shuffle both cards and reduce. After the user's map() function, the output is saved in a circular buffer. For example, when the buffer is 80% full, the overflowing thread will start executing. The spill thread dumps the contents of the buffer into a spill file. This overflow file is already partitioned by key. Within each partition, the key-value pairs are ordered by key. The reason for sorting on the map task side is to save the effort of doing a large sort on the reduction side. You can think of this as a mergesort. Below we use quicksort on each overflow file. All sorts after that are merges. After sorting, the combiner function is called if it is active. All spill files are merged into one of her MapOutputFile. Also, his MapOutputFile of every map task is collected over the network to reduce the task. Another merge (or reorder) is performed when the task is collapsed. Then the user's reduce function is called. The reason for the complication is performance optimization. Associative and commutative operators allow us to do all sorts of optimizations without sacrificing correctness. The best way to check this question is to read the Hadoop source code where all steps are clearly explained.
(Image Source: Google)